Natural Language Generation¶
In the previous tutorial we faced the problem of appropriate delexicalization of the user sentence and creation of an user dialogue act which then can be processed in the reinforcement learning module. In this tutorial we will look at the reversed problem, i.e. learning a natural language generation (NLG) model that transforms a dialogue act to the full sentence in natural language and it can be understood by an user. The NLG module has a significant impact both on usability and perceived quality of the system.
Thus, our task consists of finding a mapping from an abstract dialogue act consisting of an act type and a set of attribute-value pairs into an appropriate surface text, for example:
Dialogue act: Inform(name=Seven_days, food=Chinese)
System Output: Seven_days serves Chinese food
Before we will describe four main models that can be used in PyDial, you can play around with one of them already to see how it works and how it generates natural language sentences based on dialogue acts produced by the system by running the command:
pydial chat config/texthub.cfg
Rule-based model ¶
A convential approach to the natural language generation is to create a list of rules defining system
prompts for dialogue acts. The set of rules has variables for slot names and value names that are changed to the
specific values if we provide the dialogue act using regex expressions. You can find full of rules for all domains in semo/templates. Here we show some examples of them:
inform(name=$X,type=$U) : "$X serves $U food.";
inform(name=$X,type=$U,$Y=$O) : "$X is a nice $bU %$Y_inf($O).";
inform(name=$X,type=$U,$Y=$O,$Z=$P) : "$X is a nice $U, %$Y_inf($O) and %$Z_inf($P).";
request(type) : "What are you looking for?";
request(area) : "What part of town do you have in mind? ";
request(name) : "What is the name of the place you are looking for?";
In the case of the dialogue act from the previous section, we change variables X and U to Seven_days and Chinese based on ontology and use inform rule based on the dialogue act.
Although such an approach is theoretically very easy to implement, it requires a substantial amount of handcrafting. Thus, in next sections we look at automatic and data-driven approaches that will be not only more robust but provide better results in terms of the user experience.
You can test this model (it is implemented for all PyDial's domains) by running a command:
pydial chat config/texthub.cfg
Stochastic language generation with Recurrent Neural Networks (RNNs) ¶
An approach taken in the previous section is expensive to build because many of the processing components require a substantial amount of handcrafting which also requires expert knowledge. Moreover, such system cannot be easily adapted to new domains and the maintenance of it is a very challenging task.
That is why, the use of data-driven natural language generation methods for spoken dialogue systems might be seen as a natural solution to problems mentioned above. In PyDial library three statistical models are implemented that are based on recurrent neural networks.
An one-hot encoding $\mathbf{w}_t$ of a token is an input at each time step $t$ conditioned on a recurrent hidden layer $\mathbf{h}_t$ and outputs the probability distribution of the next token $w_{t+1}$. Because the system outputs probability vector we can sample from it which introduce randomness during generation and greatly improves the variability of generated utterances which is another advantage over rule-based systems. Finally, tokens can be lexicalised to form system utterance.
A graph below shows the standard recurrent architecture that is shared by all three models that we will describe in next sections.
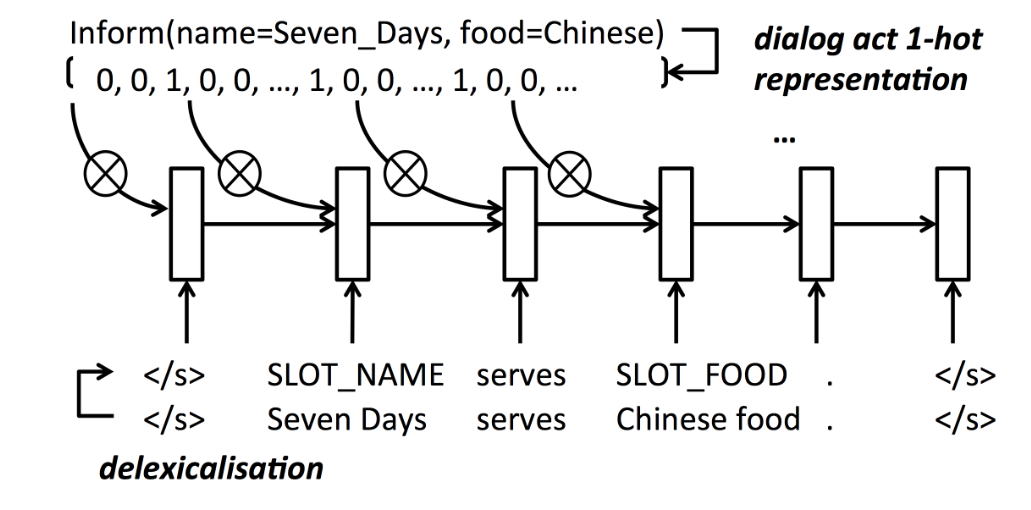
Before we will look at the differences in the architecture, you can chat with the system using one of them by running the command:
pydial chat config/texthub_rnnlg.cfg
RNN-based natural language generation model:¶
Architectures based on a stand-alone RNN cell was often found to duplicate or omit some slot-value pairs from the dialogue act. In order to force network to use the information what parts of diaogue act was used or is missing we can introduce a control vector $\mathbf{f}$ constructed from the concatenation of one-hot encodings of the required dialogue act and slot-value pairs. We use this vector at every time step using a gated version $\mathbf{f}_t$ designed to discourage duplication of information in the generated output.
In order to handle the cases when there is no explicit value to delexicalise (for example, food=dont_care, kids_allowed=false) a convolutional neural network sentence model is used to ensure that the required dialogue act and slot-value pairs are represented in the generated utterance, including the non-standard cases.
Finally, in vanilla RNNLM model the consecutive words are generated based only on the preceding history. In order to model backward contexts, after computing forward pass we use backward RNN to re-rank the candidates.
You can find more information about this model in Wen et al., 2015
In order to use this architecture, in the config file under section semo you need to choose model 'hlstm':
[semo_CamRestaurants]
semotype = RNNSemO
configfile = semo/RNNLG/config/hlstm.cfg
Currently, the architecture was implemented only in CamRestaurants domain.
Semantically Conditioned LSTM-based natural language generation model:¶
The next model that we will analyse uses LSTM cell inside the neural network architecture which helps prevent the vanishing gradient problem which makes very difficult for vanilla RNN cell to learn long range dependencies.
To ensure that the whole dialogue act is generated and to avoid duplications or omissions of slots information we can introduce again control vector $\mathbf{d}$, a one-hot representation of the dialogue act type and its slot-value pairs. Unlike in the previous section won't use simple heuristics to turn off slot feature values in the control vector but gating mechanism through control cell. Starting from the original dialogue act one-hot vector $\mathbf{d}_0$, at each time step the control cell decides what information should be retained for future time steps and discards the others, i.e.:
$$\mathbf{r}_t = f(\mathbf{w}_t, \mathbf{h}_{t-1}),$$ $$\mathbf{d}_t = g(\mathbf{r}_t, \mathbf{d}_{t-1}),$$
where $\mathbf{r}_t$ is a reading gate, $\mathbf{h}_{t-1}$ is a hidden vector from LSTM cell and $f$ and $g$ are functions that combine the information using specific operations. As previously, a one-hot encoding $\mathbf{w}_t$ of a token $w_t$ is an input at time step $t$ and the networks outputs the probability distribution of the next token $w_{t+1}$.
Adding additional layers of features proved to be effective way to improve performance in variety of tasks. In our case we can stack multiple LSTM cells on top of the dialogue act cell.
The resulting architecture has the form (in the shallow case):
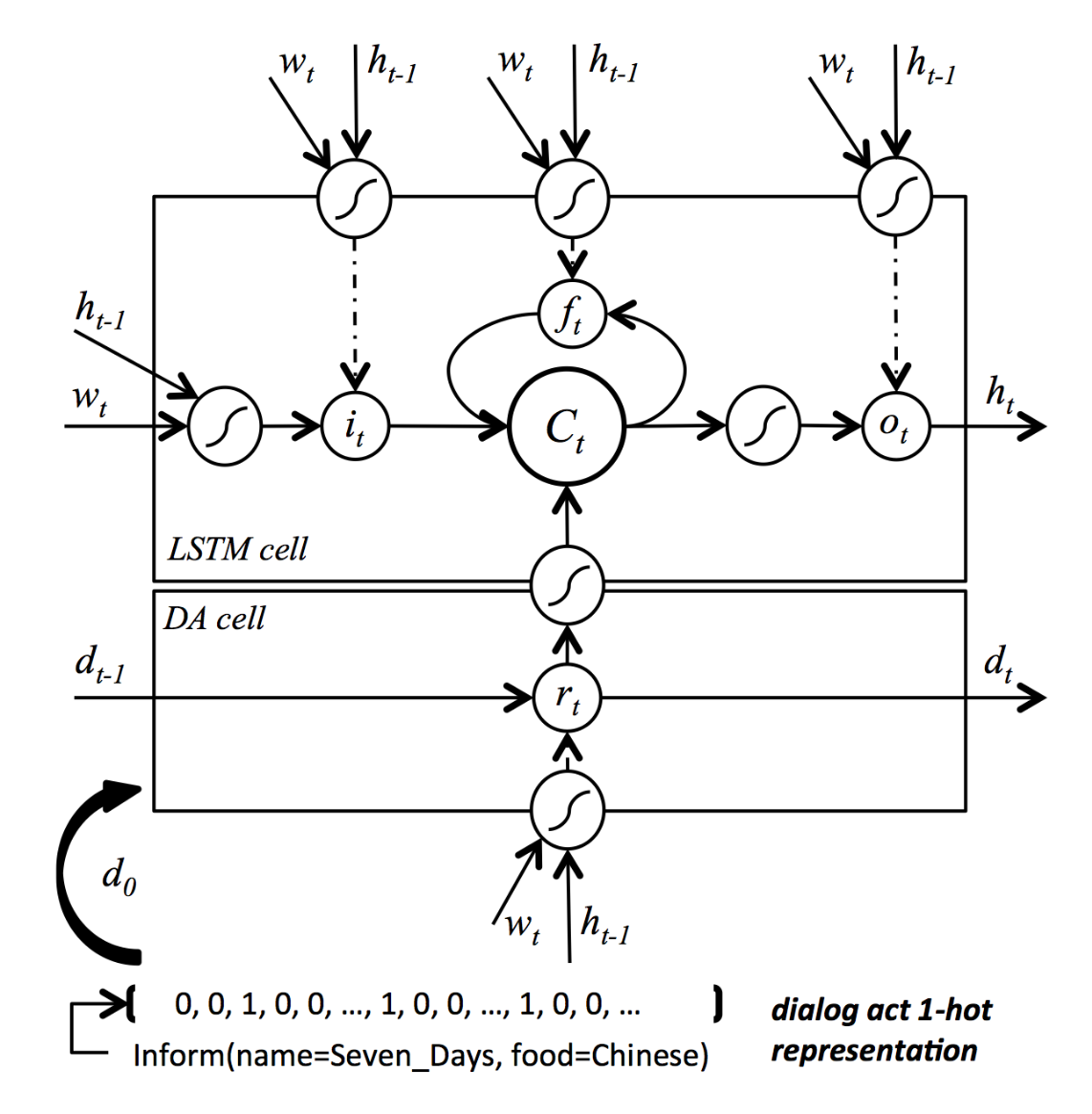
You can find more information about this model in Wen et al., 2015
In order to use this architecture (shallow one), in the config file under section semo you need to choose model 'hlstm':
[semo_CamRestaurants]
semotype = RNNSemO
configfile = semo/RNNLG/config/sclstm.cfg
Currently, the architecture was implemented only in CamRestaurants domain.
Encoder-decoder for the NLG system¶
This time, we won't feed a dialogue act at every step of the generation of the output but rather encode it to a vector representation $\mathbf{z}$ that then will be used during generation.
First, we embed each slot-value pair into its vector representation: $$ \mathbf{z}_i = \mathbf{s}_i + \mathbf{v}_i$$ where $\mathbf{s}_i$ and $\mathbf{v}_i$ are the $i$-th slot and value embedding. The dialogue act at time $t$, $\mathbf{d}_t$, is then formed using attention mechanism which at a given time $t$ use appropriate parts of the dialogue act vector. Finally $\mathbf{d}_t$ is fed to the normal LSTM cell. The figure below shows described architecture in hollistic way.
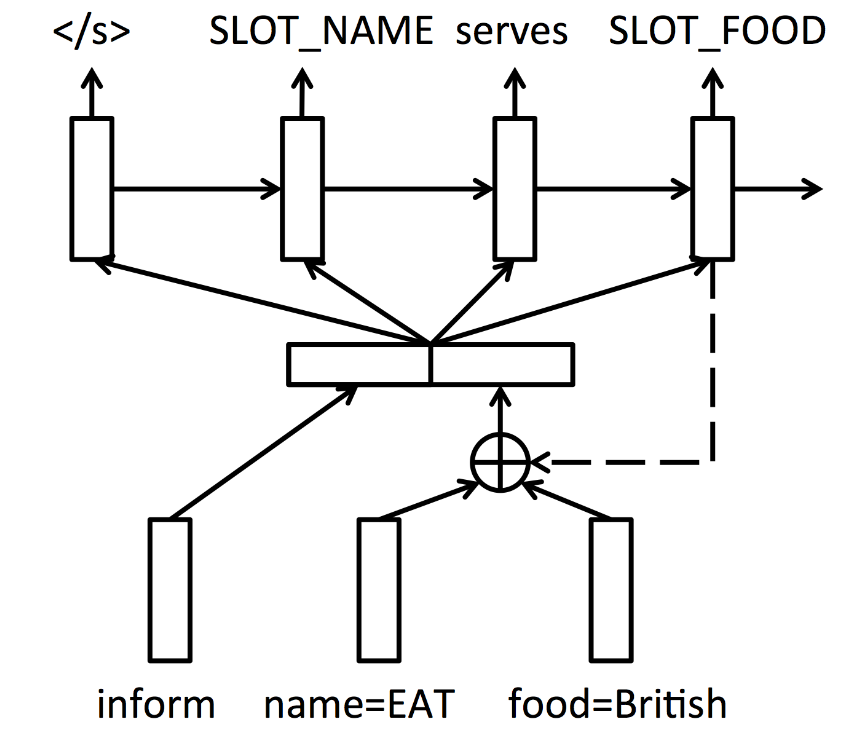
You can find more information about this model in Wen et al., 2015
In order to use this architecture, in the config file under section semo you need to choose model 'hlstm':
[semo_CamRestaurants]
semotype = RNNSemO
configfile = semo/RNNLG/config/encdec.cfg
Currently, the architecture was implemented only in CamRestaurants domain.
PyDial/semo ¶
In PyDial there is a dedicated module for natural language generation under directory semo (semantic output).
The interface class is SemO in SemOManager.py which chooses which domain to generate from.
RNN models are instantiated through RNNSemOMethods.py, which reads appropriate configuration parameters from config file. The models themselves are in semo/RNNLG where all data needed to train and test from scratch your own RNN generator are provided. The code is based on Theano. For the requirements and more detailed documentation see semo/RNNLG/README.md.
The rule-based model is implemented in RuleSemOMethods.py. It supports all domains in PyDial. The basic template generator loads a list of template-based rules from a string. These are then applied on any input dialogue act and used to generate an output string. Templates for all domains can be found in semo/templates.